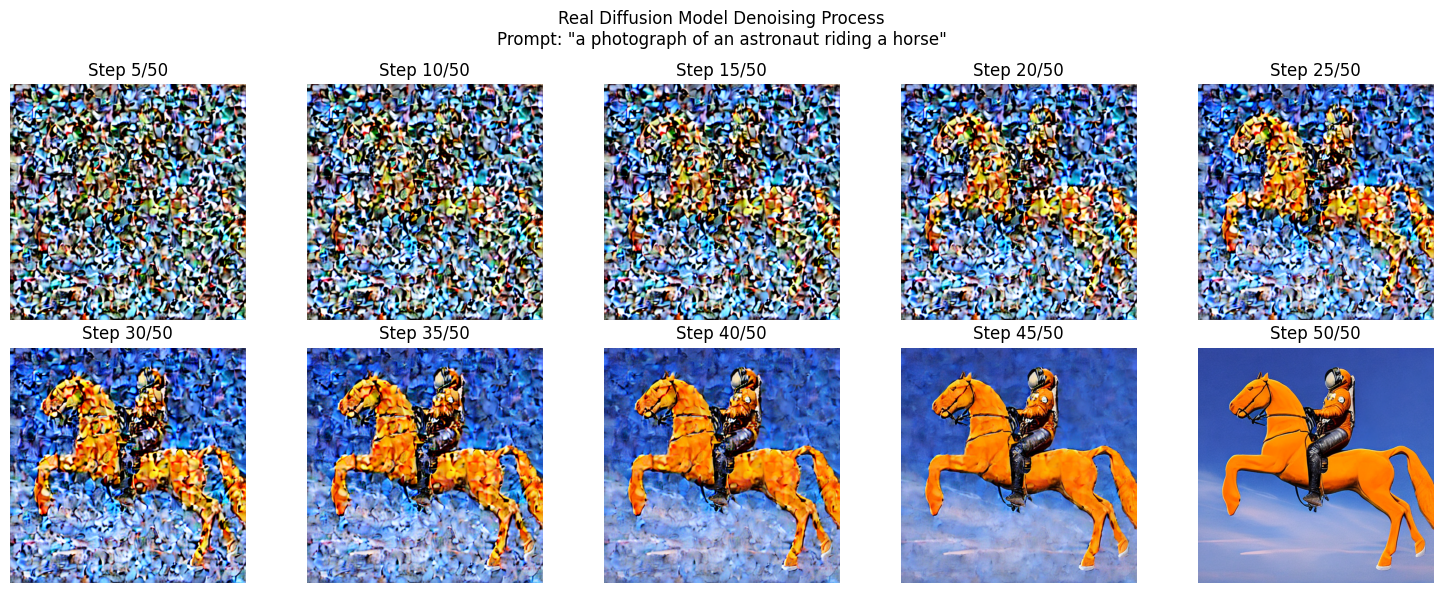
import matplotlib.pyplot as plt
import numpy as np
PROMPT = "a photograph of an astronaut riding a horse" #@param {type:"string"}
STEPS = 50 #@param {type:"slider", min:10, max:100, step:1}
SEED = -1 #@param {type:"integer"}
intermediate_images = []
def callback_fn(step, timestep, latents):
"""Capture intermediate denoising steps"""
# Decode latents to image every few steps
if step % 5 == 0 or step == 0:
with torch.no_grad():
# Decode the latent representation to an image
image = pipe.vae.decode(latents / pipe.vae.config.scaling_factor, return_dict=False)[0]
image = pipe.image_processor.postprocess(image, output_type="pil")[0]
intermediate_images.append((step, image))
result = pipe(
PROMPT,
num_inference_steps=STEPS,
callback=callback_fn,
callback_steps=1,
generator=torch.Generator().manual_seed(SEED) if SEED != -1 else None,
).images[0]
# Visualize the denoising process
num_steps_to_show = min(10, len(intermediate_images))
step_indices = np.linspace(0, len(intermediate_images)-1, num_steps_to_show, dtype=int)
fig, axes = plt.subplots(2, 5, figsize=(15, 6))
fig.suptitle(f'Real Diffusion Model Denoising Process\nPrompt: "{PROMPT}"')
for idx, step_idx in enumerate(step_indices):
row = idx // 5
col = idx % 5
step_num, img = intermediate_images[step_idx]
axes[row, col].imshow(img)
axes[row, col].axis('off')
axes[row, col].set_title(f'Step {step_num}/{STEPS}')
plt.tight_layout()
plt.savefig('diffusion_process.png', dpi=150, bbox_inches='tight')
plt.show()